 Problem Statement
Problem Statement
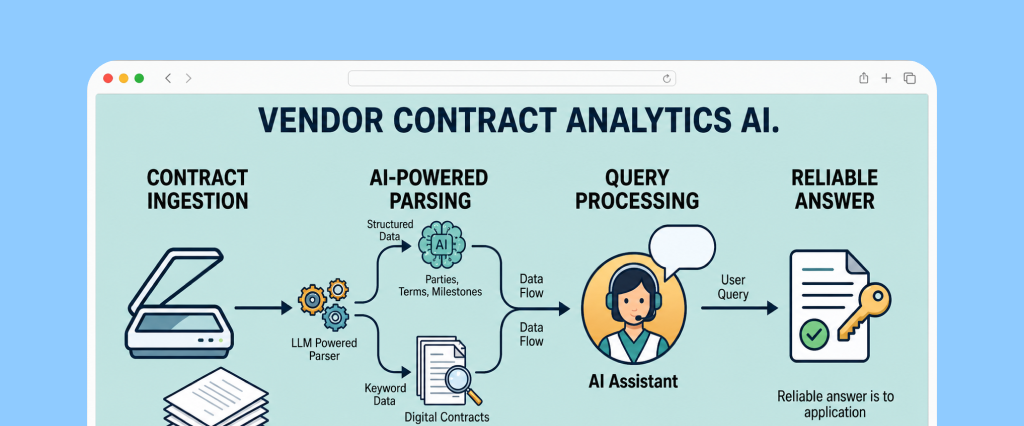
Faced with hundreds of vendor contracts, the client needed a way to transform vendor contracts into a queryable analytics layer for the business teams. The agreements existed as a mix of digital and scanned files with inconsistent formatting, complex legal structures, and deeply nested clauses.
The challenge was to build an Agentic AI assistant capable of accurately reasoning across contracts, retrieving complete clause context, and delivering reliable answers for operational and compliance decision-making.
 Why Out-of-the-Box RAG Solutions Fall Short?
Why Out-of-the-Box RAG Solutions Fall Short?
Retrieval-Augmented Generation (RAG) is frequently presented as the default architecture for document intelligence systems. However, when applied to large collections of complex legal documents, standard implementations reveal fundamental limitations.
Even with the smart chunking strategies that respect semantic boundaries, traditional RAG pipelines struggle with queries that require cross-document and multi-page reasoning, full clause reconstruction, or precise entity lookup. These issues are not edge cases but predictable structural constraints of similarity-based retrieval
Cross-contract queries return incomplete results
Questions like "Which contracts are up for renewal in the next 60 days?" or "Show me all property rental agreements in Ohio" require reasoning across the entire contract corpus - not just retrieving the top-k semantically similar chunks. A retriever optimized for local semantic similarity has no mechanism for portfolio-wide aggregation, often returning a partial or misleading answer from a subset of documents.Provides consistent and configurable logging across all jobs, enabling easier debugging and monitoring.
Clause completeness is lost when content spans beyond a single chunk
In a commercial lease, tenant maintenance obligations are rarely consolidated in one place - For example, HVAC servicing, pest control, structural repairs, and insurance requirements are typically defined across multiple sections. When a user asks "What are the tenant's maintenance obligations?", the model answers based only on the highest-scoring chunks, returning two or three items while silently omitting the rest. The answer appears complete but it is not.
Named entity lookup is unreliable
When a user searches by a specific party name, counterparty, or agreement identifier (e.g., a contract number or amendment reference), dense vector retrieval frequently fails to surface the right document. Embedding models optimize for semantic closeness, not exact entity match - so a contract referencing "ACME Corporation" may rank below semantically adjacent but contractually unrelated documents.
Polluted context produces confidently wrong answers
When the retriever pulls loosely relevant chunks from multiple contracts into a single context window, the model interpolates across them. The result is an answer that blends terms, dates, and obligations from different agreements - factually grounded in the retrieved text, but incorrect for any specific contract. This is particularly dangerous in legal and compliance workflows where precision is non-negotiabl
Solution Architecture
The solution replaces similarity-based retrieval with a two-layer intelligence system - a structured SQL layer for portfolio-wide queries and a full-document reasoning layer for contract-specific analysis. Rather than guessing which chunks are relevant, the system always knows which contract to reference and whether structured metadata is sufficient before ever loading a document.
Ingestion Pipeline
Every contract - regardless of format, scan quality, or structural complexity - passes through a standardized extraction stage at ingestion time. An LLM-powered parser reads each full document and extracts a fixed set of structured fields: contracting parties, counterparty identifiers, agreement type, governing jurisdiction, effective dates, expiry dates, auto-renewal terms, notice periods, and internal reference numbers. These fields are normalised and persisted to a relational database alongside a pointer back to the original document.
The SQL layer becomes a precise index over the entire contract corpus - not a probabilistic approximation of it.
Query Routing
Incoming queries are classified by the AI assistant before any retrieval takes place. The routing logic is built using LangGraph workflow where AI assistant smartly utilize available tools to answer user question:
Cross-contract portfolio queries
Questions like "Which agreements renew automatically in Q3?" or "List all vendor contracts in South Carolina with a liability cap below ₹50L" - are resolved entirely through SQL. The assistant translates the user's intent into a structured query, executes it against the metadata store, and returns results drawn from the full corpus. No document retrieval occurs, and no context window is polluted with irrelevant material.
Contract-specific queries
Questions about obligations, definitions, penalties, or clauses within a named or identifiable agreement - begin with a SQL lookup to locate the correct contracts. If the answer can be derived from the structured metadata alone (e.g., "When does the XYZ Services Agreement expire?"), it is answered directly. If the question requires clause-level reasoning, the full original document is loaded into the model's context window and the question is answered against complete, untruncated contract text. There is no chunking, no partial retrieval, and no risk of clause fragmentation.
Ambiguous contract references
When a query does not correctly identify a contract (e.g., "What are the payment terms in the AWS agreement?" when multiple AWS agreements exist), the assistant surfaces the candidate matches from SQL and asks the user for clarification about which contract to refer before proceeding. This eliminates silent mis-attribution.
Multi-contract reasoning
When a query spans multiple specific agreements, the assistant first uses SQL to identify the relevant contracts based on metadata such as vendor name, agreement type, or other structured filters.
Once the candidate contracts are located, each document is processed individually. The assistant loads one contract at a time, generates an intermediate answer grounded in that document’s text, and records the relevant clause-level insights. After all documents have been analysed in isolation, the assistant synthesises a final consolidated response that compares the results across contracts.
By keeping document analysis isolated per contract before aggregation, the system prevents cross-document context contamination while preserving clear attribution to the source agreement.
Technology Stack
| Layer | Technology Used |
|---|---|
| Orchestration & Agentic Framework | LangGraph / LangChain |
| GenAI model | Gemini Flash |
| Database | PostgreSQL |
| API Framework | FastAPI |
| Frontend | React WebApp |
Why This Eliminates the Core Failure Modes?
| Failure Mode | Standard RAG | This Architecture |
|---|---|---|
| Cross-document aggregation | Partial or missing results | Exact SQL aggregation over full corpus |
| Clause completeness | Silent truncation from chunking | Full document in context, no chunking |
| Named entity lookup | Unreliable vector matching | Deterministic SQL lookup by party/reference/dates etc |
| Context pollution | Blended answers from mixed chunks | Single-document context per answer |
| Ambiguous contract identity | Silently picks wrong document | Asks user for clarification |
 Conclusion
Conclusion
Vendor contract intelligence is a domain where the cost of a wrong answer extends beyond inconvenience - a missed renewal, an unenforceable clause, or a compliance gap can carry real business consequences. Standard RAG architectures, despite their appeal as general-purpose document Q&A solutions, introduce failure modes that are both predictable and difficult to detect, making them poorly suited for legal workflows where precision is non-negotiable.
The architecture described here resolves this by making a clean structural separation: SQL for portfolio-wide queries, full-document context for clause-level reasoning. This eliminates incomplete retrieval, fragmented clause context, and cross-document contamination at their root rather than trying to work around them.
The result is a system that business and compliance teams can genuinely rely on - one that answers with the accuracy of a database when aggregating across contracts, the completeness of a human reviewer when reasoning within one, and the transparency to ask for clarification rather than guess when contract identity is ambiguous.
Empower Your Business With Cutting-edge IT Solutions
Unlock Innovation and Growth with Our Expert Solutions